
Broadcast Layer¶
Overview¶
The Broadcast distributed data movement primitive copies data from one worker (or set of workers) to another.
In DistDL, broadcasts map data from tensors on one partition to copies of those tensors on another partition. The broadcast operation applies for partitions with and without a (Cartesian) topology. Topologies may be mixed if the requirements supporting the Broadcast Rules are satisfied.
For the purposes of this documentation, we will assume that an arbitrary global input tensor \({x}\) is partitioned by \(P_x\) and that another partition \(P_y\) exists.
Note
The definition of a broadcast in DistDL goes beyond the classical parallel
broadcast operation, for example, MPI_Bcast() in MPI. Such broadcasts
typically assume 1-dimensional arrays, broadcast within a group of workers,
and neither impose nor exploit topological structure on the set of workers.
Motivation¶
In distributed deep learning, there are many applications of the broadcast primitive. Depending on computation distribution, and thus partition structure, any tensor in a distributed layer may need to be broadcast. For example, in distributed Convolution Layers, a simple partition of the input tensor in feature space only requires that (small) weight and bias tensors need to be broadcast to all workers. In distributed Linear Layers, the weight tensor is partitioned and the input tensor needs to be broadcast along the flattened feature dimension.
Implementation¶
A back-end functional implementation supporting DistDL
Broadcast must follow the
Broadcast Rules and must also support the
following options:
transpose_src, a boolean which tells the broadcast algorithm to transpose \(P_x\) by implicitly reversing its shape. (DefaultFalse)transpose_dest, a boolean which tells the broadcast algorithm to transpose \(P_y\) by implicitly reversing its shape. (DefaultFalse)preserve_batch, a boolean which tells the broadcast algorithm to ensure that any zero-volume outputs retain the batch size, or first dimension shape, of the input tensor. (DefaultTrue)
Note
While it may appear that transpose_src and transpose_dest will have
equivalent impact, this is not true because we allow \(\text{dim}(P_x)
< \text{dim}(P_y)\). Moreover, when it is true that they are equivalent,
there can be semantic information conveyed by the choice of which partition
to transpose.
To support some slightly different broadcast patterns, users can implicitly transpose the input or output partitions. In either transposition, the shape of the partition is implicitly reversed but the structure of the input or output tensor is not changed.
Assumptions¶
The broadcast operation is not in-place. Even if a worker is both a data source and a data destination and even if that data is the same (i.e., the operation is locally an identity), a Torch
.clone()of the tensor is returned.A worker may be active in the input partition, output partition, both partitions, or neither partition.
If a worker is active in both partitions, it may return different data than it takes as input.
Forward¶
The forward operation copies tensors from \(P_x\) to \(P_y\), along the broadcastable dimensions of the input partition.
A worker that is active in \(P_x\) and \(P_y\) will take a subtensor of \(x\) as input and return a (potentially different) subtensor of \(x\) as output.
A worker that is active only in \(P_x\) will take a subtensor of \(x\) as input and return a zero-volume tensor, optionally with the same first dimension (batch size) as the input.
A worker that is active only in \(P_y\) will take a zero-volume tensor as input and return a subtensor of \(x\) as output.
A worker that is active in neither partition will take a zero-volume tensor as input and return a clone of that tensor as output.
This class provides only an interface to the back-end implementation of the forward algorithm. This interface does not impose any mechanism for performing this copy. Performance details and optimizations are back-end dependent.
The back-end forward operation is implemented through the PyTorch autograd functional interface and
called through the Broadcast forward() function.
Adjoint¶
The adjoint (backward) operation sum-reduces tensors from \(P_y\) back to \(P_x\), along the broadcastable dimensions of the input partition.
A worker that is active in \(P_x\) and \(P_y\) will take a subtensor of \(\partial x\) as input and return a (potentially different) subtensor of \(\partial x\) as output.
A worker that is active only in \(P_x\) will take a zero-volume tensor as input and return a subtensor of \(\partial x\) as output.
A worker that is active only in \(P_y\) will take a subtensor of \(\partial x\) as input and return a zero-volume tensor, optionally with the same first dimension (batch size) as the original tensor \(x\).
A worker that is active in neither partition will take a zero-volume tensor as input and return a clone of that tensor as output.
This class provides only an interface to the back-end implementation of the adjoint algorithm. This interface does not impose any mechanism for performing this sum-reduction. Performance details and optimizations are back-end dependent.
The adjoint operation (PyTorch grad function class) is generated automatically
via autograd and calls the backward() function implemented by the back-end
functional interface.
Broadcast Rules¶
DistDL Broadcast layers broadcast along partition
dimensions following rules similar to the NumPy broadcast rules.
Tensors mapped onto DistDL partitions will broadcast (copy) along a dimension
when
the shape of \(P_x\) in that dimension matches the shape of \(P_y\) in that dimension, or
the shape of \(P_x\) in that dimension is 1.
The major difference between these broadcast rules and the NumPy broadcast rules are that Rule 2 for NumPy arrays allows the either array to have shape 1 in that dimension, but in DistDL, only the input partition can have shape 1. Like NumPy, \(P_x\) and \(P_y\) do not have to have the same shape, however, it is required that \(\text{dim}(P_x) \le \text{dim}(P_y)\). When the dimensions do not match, \(P_x\) is implicitly extended to the left with ones until the dimension does match.
In the following examples, subtensors are defined by the black partition borders. There is one worker per subtensor in each partition. Like colors indicate subtensors that interact in the broadcast. For example, the blue subtensor in \(P_x\) broadcasts to the blue subtensors in \(P_y\).
Standard Broadcasts¶
Example 1¶
A partition with shape \(1\) broadcasts to a partition with shape \(4\). The shape of the tensor is irrelevant.
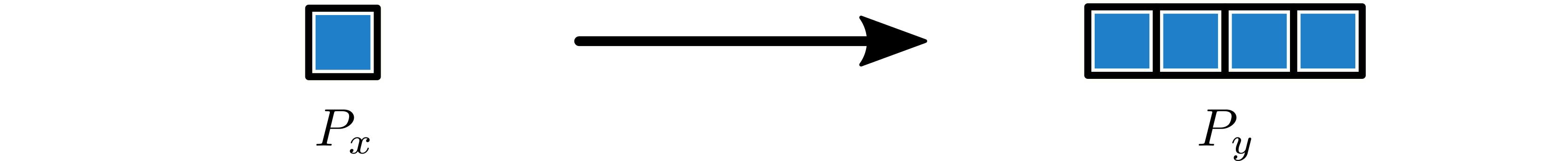
Example 2¶
A partition with shape \(1\) broadcasts to a partition with shape \(2 \times 3\). \(P_x\) is implicitly extended to \(1 \times 1\).

Example 3¶
A partition with shape \(3 \times 1\) broadcasts to a partition with shape \(3 \times 4\).

Example 4¶
A partition with shape \(1 \times 1 \times 3\) broadcasts to a partition with shape \(4 \times 4 \times 3\).

Example 5¶
A partition with shape \(1 \times 1 \times 3\) does not broadcast to a partition with shape \(3 \times 3 \times 2\).

Example 6¶
A partition with shape \(1 \times 3\) does not broadcast to a
partition with shape \(3 \times 1\). If either transpose_src or
transpose_dest are True, then this will broadcast. However, it will
not be an identity broadcast because there is no guarantee that no
data movement is required.

Broadcasts with transpose_src = True¶
When transpose_src is True, the shape of the input partition is
implicitly reversed. Thus, if \(P_x\) has shape \(1 \times 3 \times
4\), the broadcast behaves as if it is has shape \(4 \times 3 \times 1\).
Note
If \(P_x\) has shape \(3 \times 4\), the transpose occurs before the left side is padded with ones, so the effective shape is \(1 \times 4 \times 3\).
Example 7¶
A partition with shape \(1 \times 3\) broadcasts to a partition with shape
\(3 \times 4\) if transpose_src = True.

Broadcasts with transpose_dest = True¶
When transpose_dest is True, the shape of the output partition is
implicitly reversed. Thus, if \(P_y\) has shape \(1 \times 3 \times
4\), the broadcast behaves as if it is has shape \(4 \times 3 \times 1\).
Example 8¶
A partition with shape \(4 \times 1\) broadcasts to a partition with shape
\(3 \times 4\) if transpose_dest = True.
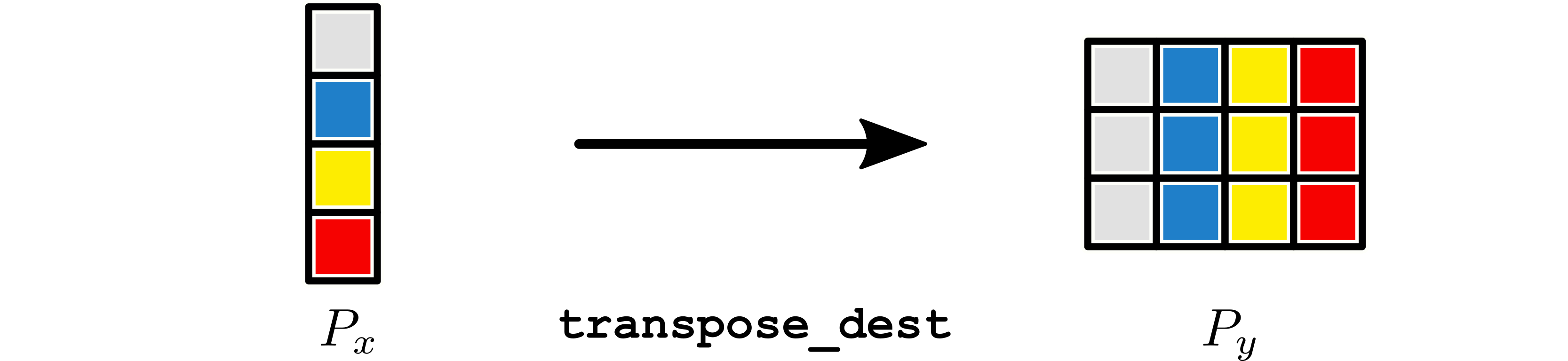
Examples¶
To replicate a 2-dimensional tensor that is partitioned by a 1 x 3 partition
onto a 4 x 3 partition:
>>> P_x_base = P_world.create_partition_inclusive(np.arange(0, 3))
>>> P_x = P_x_base.create_cartesian_topology_partition([1, 3])
>>>
>>> P_y_base = P_world.create_partition_inclusive(np.arange(0, 12))
>>> P_y = P_y_base.create_cartesian_topology_partition([4, 3])
>>>
>>> x_local_shape = np.array([7, 5])
>>>
>>> layer = Broadcast(P_x, P_y, preserve_batch=False)
>>>
>>> x = zero_volume_tensor()
>>> if P_x.active:
>>> x = torch.rand(*x_local_shape)
>>>
>>> y = layer(x)
Here, 4 copies of each subtensor of \({x}\) will be created.