
Using DistDL¶
Installation¶
At the command line:
pip install distdl
Usage¶
To use DistDL in a project:
import distdl
Design Philosophy¶
DistDL provides a “model parallelism” for deep learning, built on the PyTorch library.
Most parallelism in deep learning toolkits arises from “data parallelism,” which essentially relies on the fact that different input data, often grouped into batches, have independent impact on the trained network and can thus be assimilated in embarrassingly parallel fashion.
Model parallelism has been more challenging to achieve, partially because it is not as well-defined in the context of deep neural networks. Traditionally, e.g., in the context of PDE solvers, the model to be parallelized comes from a spatial decomposition of the physical properties driving the simulation. In a general neural network, such an abstraction does not exist. Instead, we have tensors, many of which only have tenuous connection to reality and often have no auxiliary structure over which we can decompose a problem.
As a result, DistDL approaches the distributed deep learning problem by assuming the optimal decomposition for any and all tensors in the network should drive the decomposition. Here, the definition of optimal is entirely problem, computing system, and network architecture dependent.
We provide a general framework from which optimal implementations of our data movement primitives for distributed tensors can be implemented. This framework is designed to allow fine tuning of back-ends that are optimal for a variety of parallel computer architectures, communication back-ends, and optimality criteria.
To reflect this generality, we attempt to eschew some back-end specific terminology, and generally assume that parallel computation is performed by a number of workers that communicate with each other using data movement primitives. We will refer to a collection of workers as a team of workers.
Tensors¶
DistDL assumes that tensors representing inputs, outputs, and network parameters
are PyTorch torch.Tensor objects.
Warning
Current implementation restrictions require these tensors to be on the cpu
device and that they can be contiguously viewed as a NumPy array.
This restriction will be lifted in future versions.
Zero-volume Tensors¶
Occasionally, there are more workers available than are required to store and compute over a distributed tensor. Some distributed layers may require more workers to store their outputs than are required to store the inputs, or vice versa. Also, some layers (for example distributed linear layers) may require more workers to perform computation than are required to store the inputs and outputs. In these cases and because all workers in a given team may be needed, DistDL occasionally expects tensors with zero-volume as input or output.
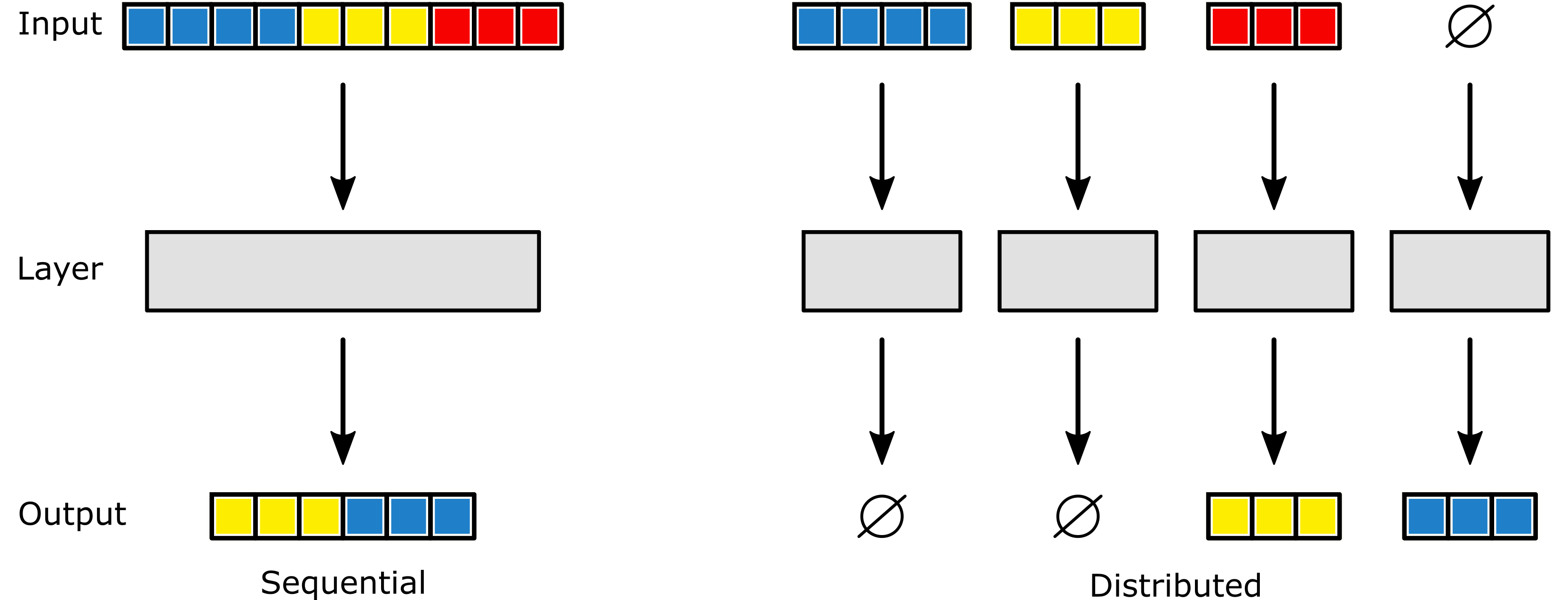
(left) A sequential layer, with size 10 input and sized 6 output. (right) A distributed layer, performing the same operation, but with an input partition using the first 3 of the 4 workers and an output partition using the last 2 of the 4 workers. \(\varnothing\) indicates a zero-volume input or output.¶
In PyTorch, a tensor with zero-volume is one that has a shape containing a zero.
A convenience function, distdl.utilities.torch.zero_volume_tensor, is
provided to aid in the creation of these tensors.
Tensor Partitions¶
At the core of DistDL is the concept of the tensor partition. In DistDL, any tensor may be a distributed tensor. Distributed tensors generally fall into two categories:
tensors distributed over workers with no implicit or explicit ordering induced by a topology, and
tensors distributed over workers that have an implicit or explicit ordering induced by a Cartesian topology.
Tensors in the former category often appear when a copy of the single tensor
is needed by multiple workers. For example the weight tensor for a simple
convolutional layer will be needed on multiple workers, if each worker is
responsible for applying the kernel to a portion of the input tensor. Tensor
partitions over tensors in this class are created using the back-end
implementation of the Partition class.
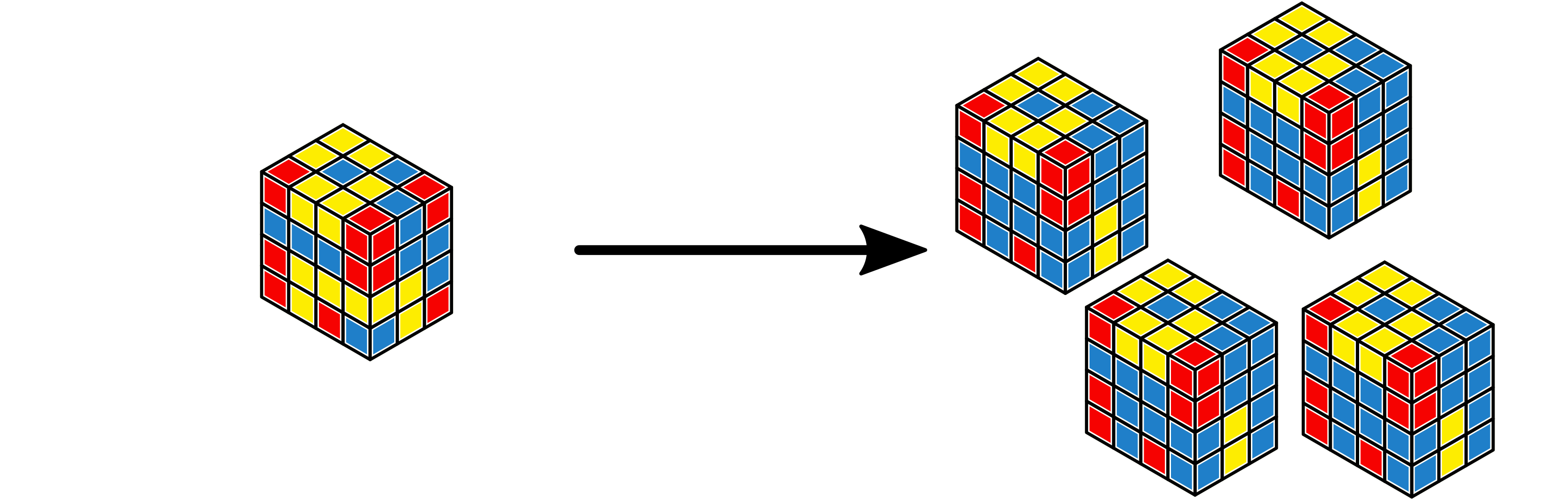
A \(4 \times 4 \times 3\) tensor replicated onto a partition of size 4 with no topology.¶
Note
When tensors are distributed over a partition using replication in a forward pass, the gradient tensors that appear on the partition are not necessarily copies of each other.
Tensors in the latter category generally appear as input and outputs of
distributed layers, where each worker is responsible for processing only a
portion of the input and producing a portion of the output. Tensor partitions
over tensors in this class are created using the back-end implementation of
the CartesianPartition class.
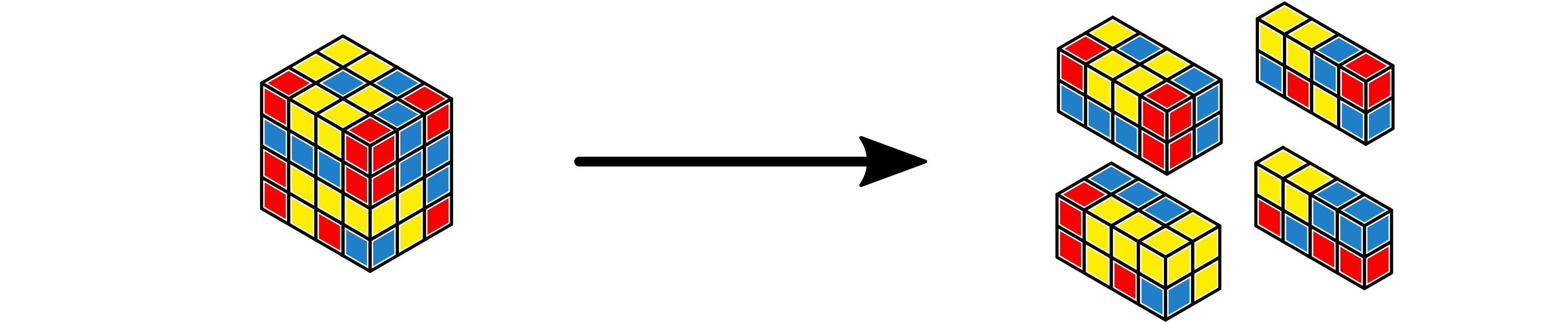
A \(4 \times 4 \times 3\) tensor partitioned onto a partition of size 4 with a \(1 \times 2 \times 2\) Cartesian topology.¶
The technical structure of each of these partitions is back-end specific. See the Code Reference for the back-end back-end for implementation details.
Distributed Layers¶
DistDL defines a number of distributed layer functions, implemented as PyTorch modules, which allow distributed neural networks to be constructed in the same way PyTorch allows sequential networks to be constructed.
DistDL distributed layers are implemented following the linear algebraic model provided in the paper *A Linear Algebraic Approach to Model Parallelism in Deep Learning*. Specific details of the interface are documented in the Code Reference and back-end specific details are documented with that back-end.
All layers are assumed to be inductively load-balanced. That is, their output should be load balanced so that each worker does approximately equal work. Consequently, it is assumed that the inputs are also load balanced, as a load balanced output from one layer is the input to the next.
Defining A Distributed Network¶
A detailed example is a work-in-progress. For now, see the DistDL examples repository for an example of a simple distributed network.